yori - 内存 & 多路复用 & 网络模型
内存回收
过期key的处理
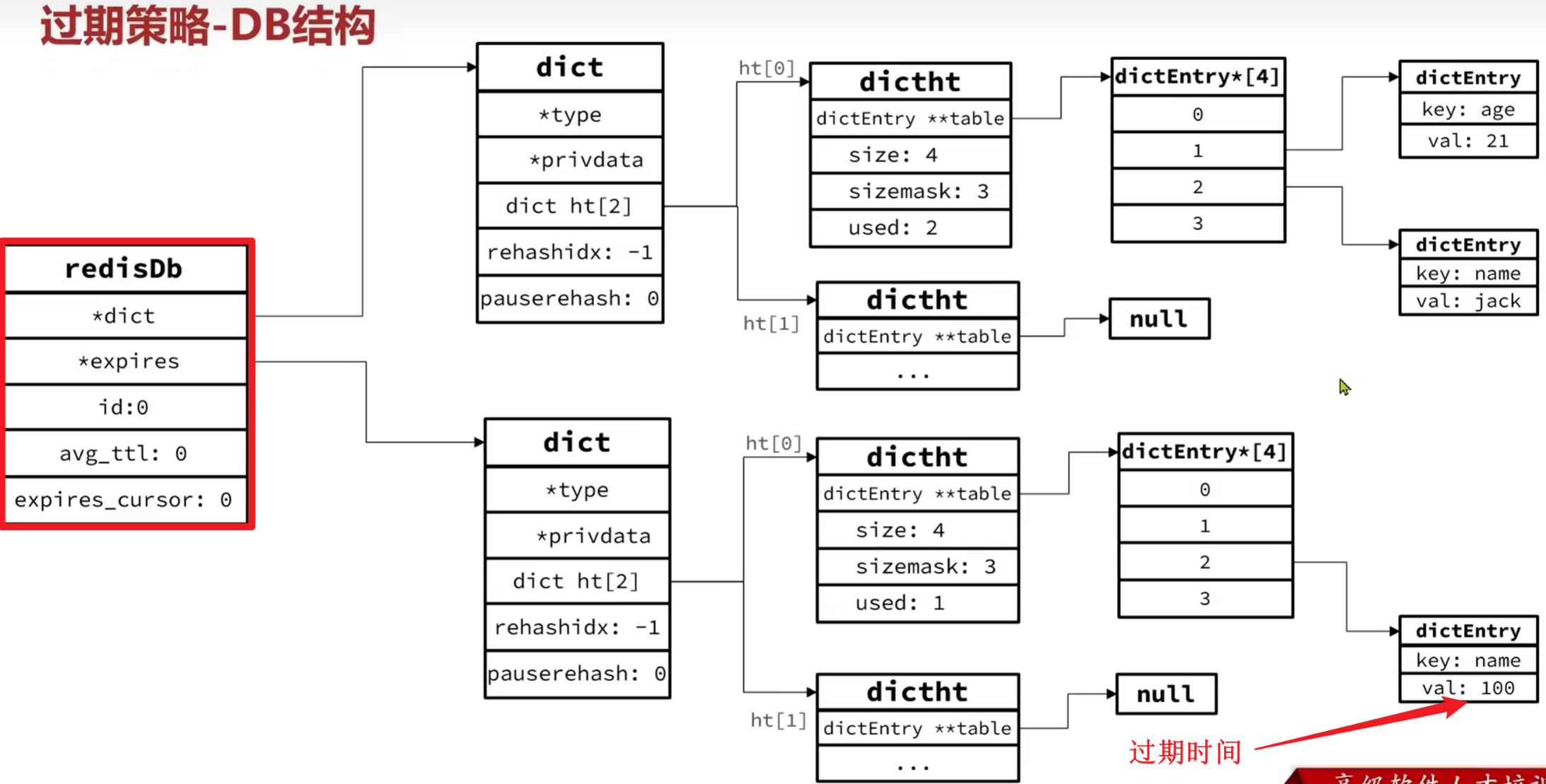
RedisDB
1 | // redisDb —— Redis 的一个逻辑数据库(默认 16 个) |
删除
惰性删除
如果想已过期就立即删除, 那么就要给每个key安装监视器,
成本巨大, 因此我们使用懒删除, 访问到key时查看是否过期, 是则删除
周期删除
抽样删除 (有些key已过期但很少人访问可能造成长期内存浪费)
- Redis会设置一个定时任务 serverCron(), 按照server.hz 频率来执行过期key清理, 模式为 SLOW
- Redis的每个事件循环前会调用 beforeSleep()函数, 执行过期key清理, 模式为FAST
slow模式
- 执行清理耗时不超过一次执行周期的25%
- 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样否则结束
fast模式 (过期key比例小于10%不执行)
- 执行清理耗时不超过1ms
- 执行频率受beforeSleepO调用频率影响,但两次FAST模式间隔不低于2ms
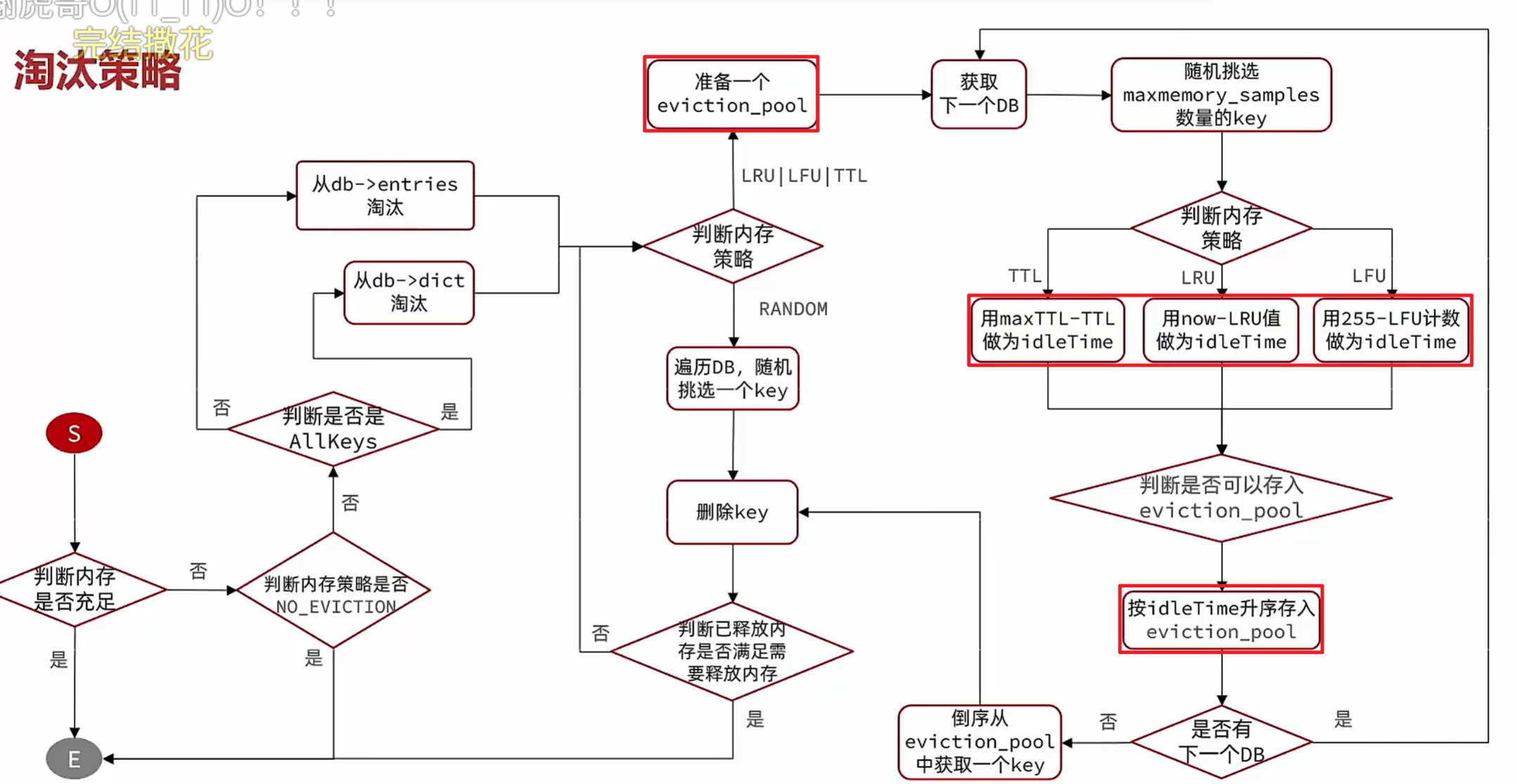
内存淘汰策略
🧱 默认策略
- noeviction
- 不淘汰任何 key
- 内存满 → 写报错(默认)
🎯 volatile(只淘汰有 TTL 的 key)
- volatile-ttl : TTL 越小 → 越先删
- volatile-random : 随机删
- volatile-lru : 最近最少使用
- volatile-lfu : 使用频率最低
🌍 allkeys(淘汰所有 key)
- allkeys-random : 随机删
- allkeys-lru : 最近最少使用
- allkeys-lfu : 使用频率最低
⚡ LRU vs LFU
- LRU:看时间(最近是用最少)
- LFU:看次数(使用频率最少, 少的先淘汰)
LFU
Redis的数据都会被封装为RedisObject结构
1 | typedef struct redisObject { |
LFU记录的访问次数是逻辑访问次数, 意即: 并不是所有key被访问都计数
而是通过运算:
- 生成0~1之间的随机数 R
- P = $\frac{1}{\text{旧次数 } \cdot \text{ lfu_log_factor } + 1}$, lfu_log_factor默认为10
- R < P, 则 cnt++, 最大不超过255
- 访问次数随时间衰减, 距离上一次访问时间每隔lfu_decay_time分钟 (默认1),cnt–
逻辑访问函数
1 | unsigned char LFULogIncr(unsigned char counter) { |
- 每次访问不一定+1, counter越大, 增长越慢
- 大访问量不会让cnt增长太离谱
逻辑衰减
1 | int lfuDecayAndReturn(robj* o){ |
多路复用
socket读操作
- 阶段一:数据准备阶段(内核态)
- 网卡 → 内核缓冲区
- 数据还没到 / 没准备好
- 这时候
recvfrom会卡在这一步, 真正的瓶颈
- 阶段二:数据拷贝阶段(内核 → 用户态)
- 内核缓冲区 → 用户缓冲区
- 这一步通常很快(内存拷贝)
阻塞 & 非阻塞 -> CPU浪费
无论是阻塞IO / 非阻塞IO, 用户在一阶段都需要调用recvfrom获取数据,
差别在于无数据时的处理方案:
- 恰好无数据, 阻塞IO会使进程阻塞, 非阻塞会使CPU空转
- 恰好有数据, 则用户进程可以直接进入第二阶段, 读取并处理数据
单线程
只能依次处理每个socket, 如果正在处理的socket未就绪(data不可读 / 不可写), 线程就会阻塞, 所有其他客户端都必须等待
服务员一直在等一个顾客点餐
- 顾客思考吃啥
→ 阶段一:等数据准备 - 顾客点餐
→ 阶段二:读取数据
优化思路
方案一:多线程(堆人力)
- 一个线程处理一个 socket
- 优点:简单粗暴
- 缺点:
- 上下文切换重
- 内存占用高
- 线程爆炸
方案二:IO 多路复用
核心思想:
1 | 不要盯一个 socket 等 |
实现方式:
- select / poll / epoll
效果: - 单线程可以处理多个 socket
- 不阻塞在某一个连接上
IO多路复用
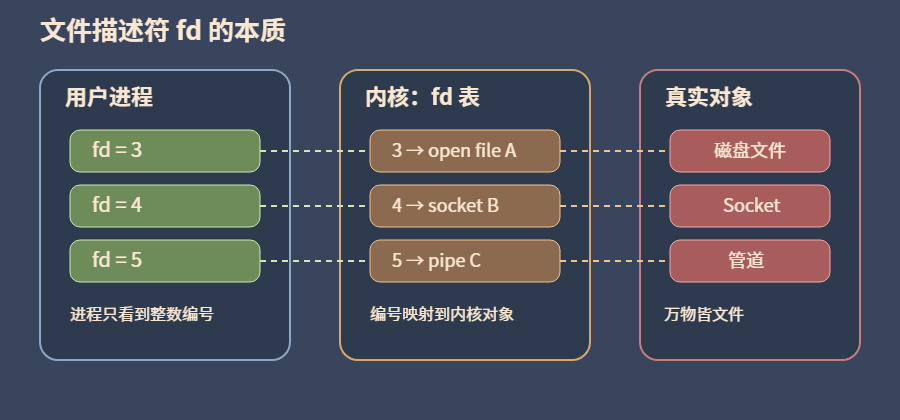
文件描述符
当进程调用 open(“a.txt”) 时,内核不会直接把文件内容交给进程。
而是在内核中建立一条访问关系:
- 找到目标文件对应的 inode,并检查访问权限
- 为此次打开操作创建一个 struct file来记录本次打开的状态,
如读写位置、打开标志、访问模式等 - 接着在当前进程的文件描述符表中找一个空闲位置,
让它指向这个 struct file - 最后把这个位置的下标返回给进程,这个整数就是文件描述符 fd
也即 :
fd → struct file → inode → 磁盘数据块
其中:
- fd:进程里的编号,是访问入口
- struct file:一次打开操作对应的运行时状态
- inode:文件本体的元数据
真正读取文件内容通常发生在后续 read/write 阶段
fd 是门牌号,struct file 是本次会话,inode 是文件档案,数据块才是真货
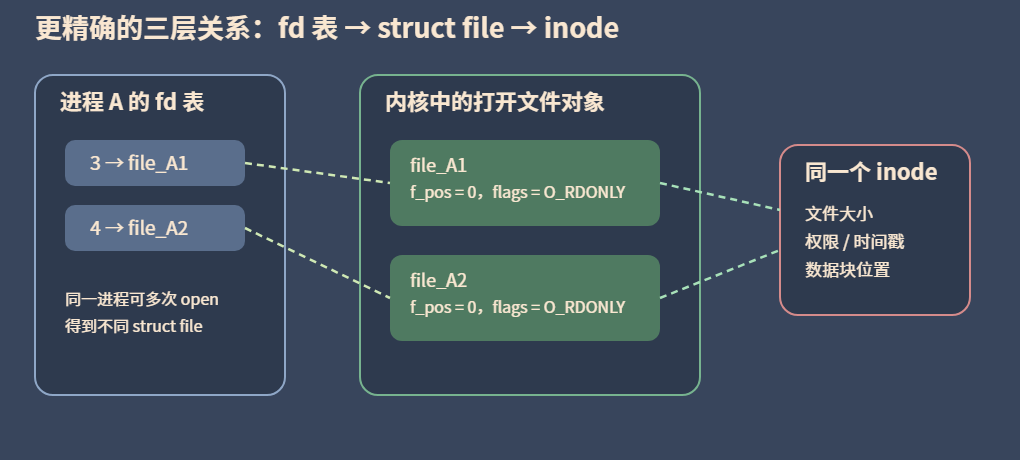
常见的文件描述符
| fd | 含义 | 对应 |
|---|---|---|
| 0 | 标准输入 | stdin |
| 1 | 标准输出 | stdout |
| 2 | 标准错误 | stderr |
 |
IO多路复用原理
利用单个线程同时监听多个FD, 某个FD可读、可写时得到通知
select方法
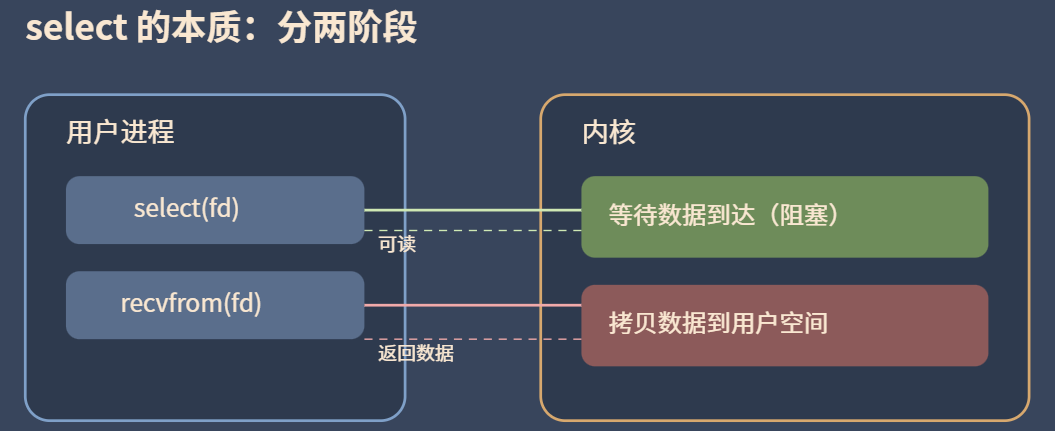
code
1 | long int fd_mask; |