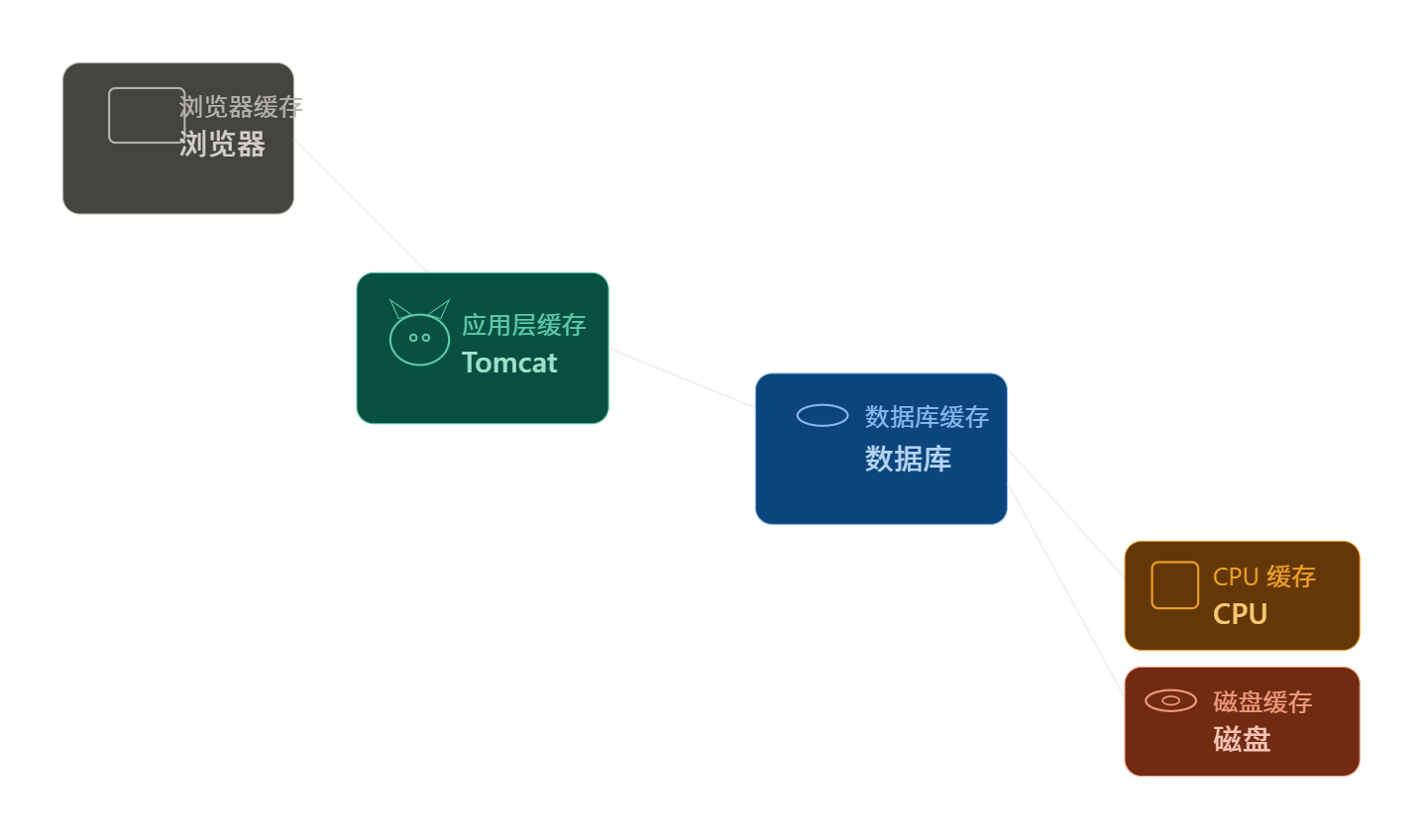
缓存
缓存就是数据交换的缓冲区,
是存贮数据的临时地,一般读写性能较高
添加商户缓存
Mybatis查询用户提供 query.function()各种函数

queryById
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public Result queryShopById(Long id){
String key = CACHE_SHOP_KEY + id;
String val = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isNotBlank(val)){
Shop valToBean = JSONUtil.toBean(val,Shop.class);
return Result.ok(valToBean);
}
Shop shop = getById(id);
if(shop==null) return Result.fail("店铺不存在");
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJSONStr(shop));
return Result.ok(shop);
}
|
queryByType
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@Override
public List<ShopType> queryByShopType(){
String key = "shop:type";
String val = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isNotBlank(val)) return JSONUTil.toList(val,ShopType.class);
List<ShopType> typeList = query().orderByAsc("sort").list();
if(typeList==null) return new ArrayList<>();
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJSONStr(typeList));
reture typeList;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
List<String> range = stringRedisTemplate.opsForList()
.range(key,O, -1);
if (range != null && !range.isEmpty()) {
return range.stream()
.map(s -> JsoNUtil.toBean(s,ShopType.class))
.collect( Collectors.toList() );
}
List<ShopType> typeList = query().orderByAsc("sort").list();
if (typeList == null) return new ArrayList<>();
typeList.forEach(ShopType t -> stringRedisTemplate.opsForList()
.rightPush(key, JSoNUtil.toJsonStr(t)));
return typeList;
|
实现商铺的缓存和数据库的双写一致
先更新数据库, 再删除缓存, 下次访问在缓存找, 没找到再写缓存
1
2
3
4
5
6
7
8
9
10
11
12
| @Override
public Result updateShop(Shop shop){
Long id = shop.getId();
if(id==null) return Result.fail("店铺id为空");
updateById(shop);
stringRedisTemplate.delete(CAHE_SHOP_KEY+shop.getID());
return Result.ok();
}
|
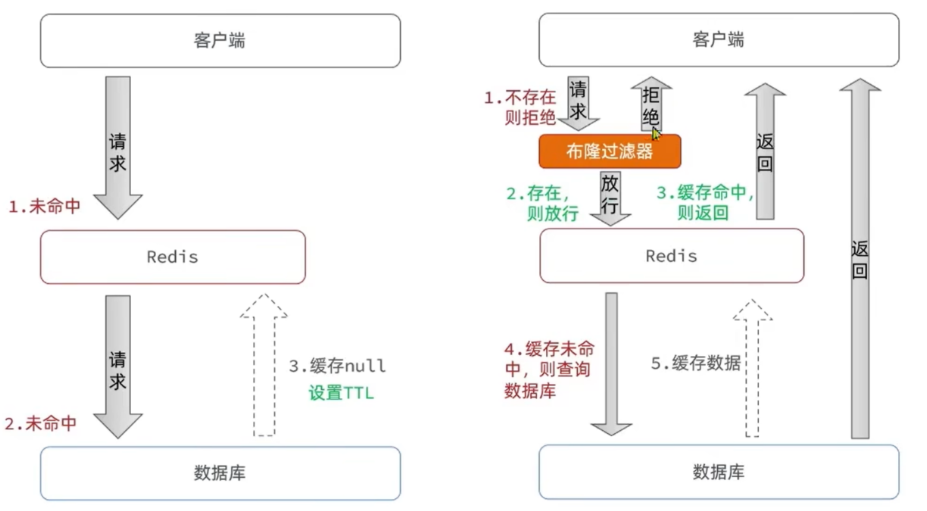
缓存穿透 - 不存在的data
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
不断的请求缓存和数据库中都不存在的数据, 可能导致数据库的崩溃.
flowchart LR
C[客户端] --|1. 未命中|--> R[Redis]
R --|2. 未命中|--> DB[数据库]
解决方案:
缓存空对象 NonKey->Null
实现简单, 但是额外内存消耗, 短期的不一致
布隆过滤 (言假必定假)
hash+二进制位 来判断是否有
其他方案
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
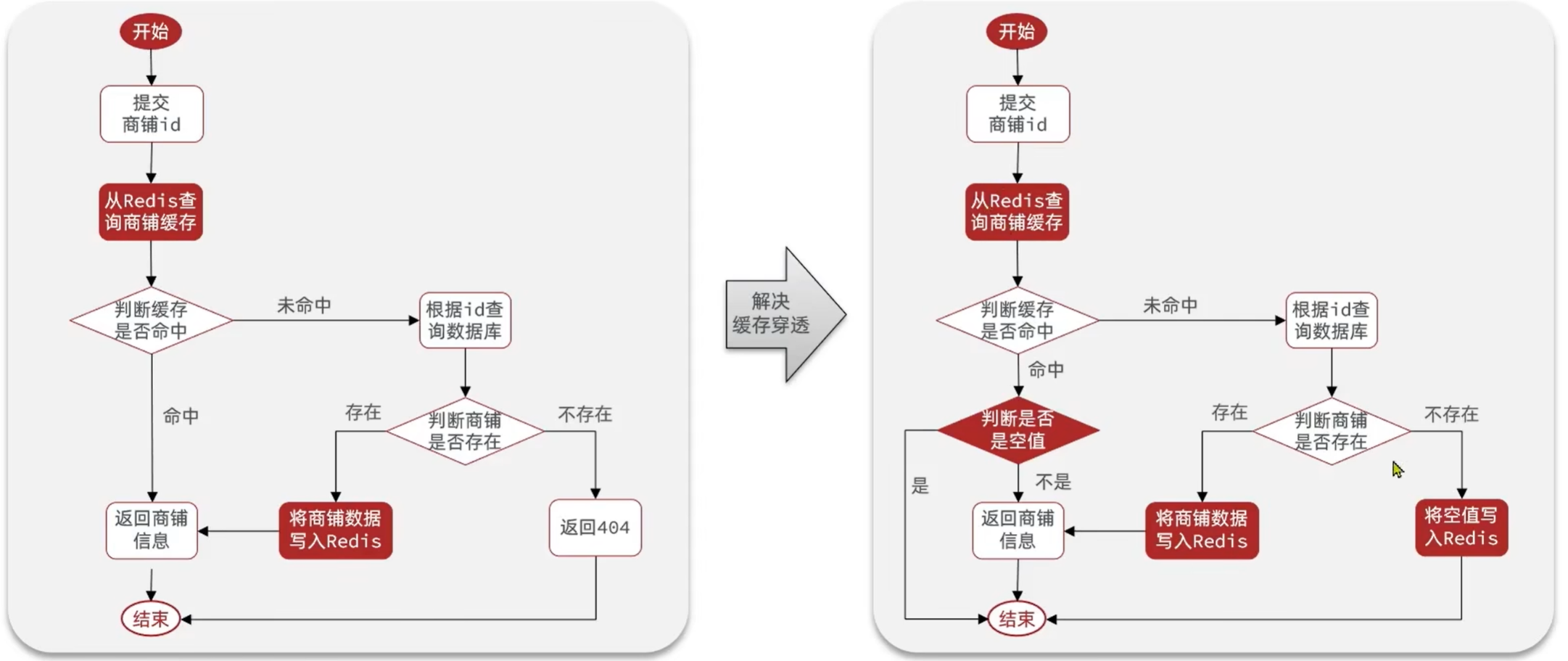
我们在生产中常用的是赋空值 “”
大概流程:
1.redis查询数据
2.判断是不是有数据的 isblank
3.判断是不是””,fail
4.只能是null了,走数据库
5.数据库找到为null,则redis缓存空值 “”,fail
6.非null,写入redis并返回数据
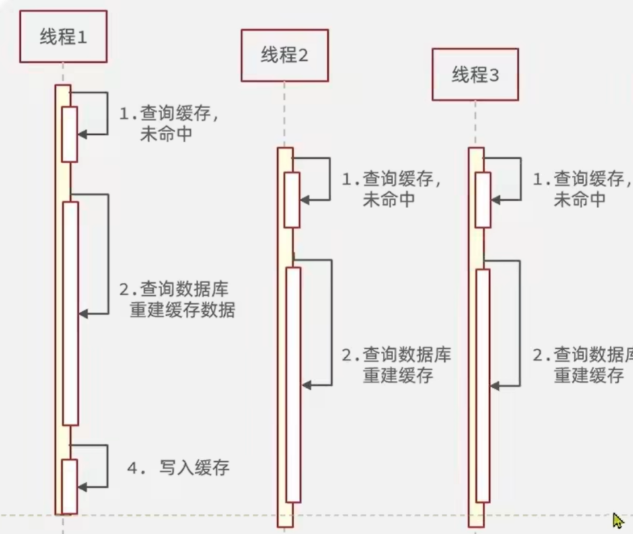
缓存击穿
一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
| 解决方案 |
优点 |
缺点 |
| 互斥锁 |
没有额外的内存消耗 |
线程需要等待,性能受影响 |
|
保证一致性 |
可能有死锁风险 |
|
实现简单 |
|
| 逻辑过期 |
线程无需等待,性能较好 |
不保证一致性 |
|
|
有额外内存消耗 |
|
|
实现复杂 |
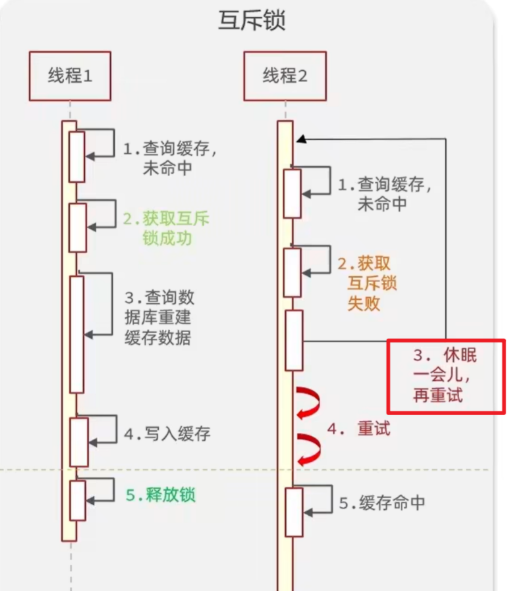
互斥锁
缓存击穿的互斥锁属于悲观锁的一种应用
——为了避免并发冲突而先加锁,
只不过它是跨进程或者跨服务的分布式锁形式,
不是数据库内部的锁。
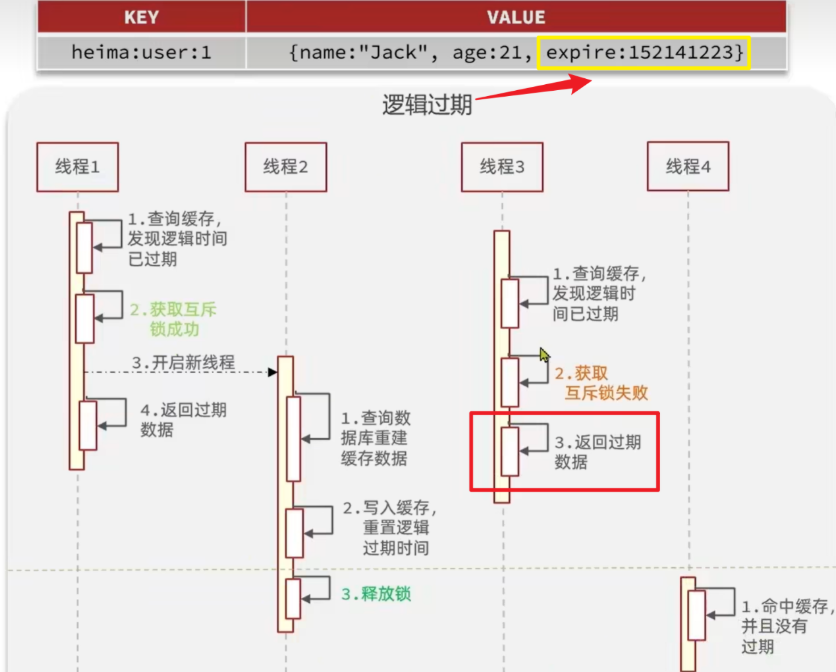
逻辑过期
设置逻辑过期时间,
发现过期则加锁异步刷新, 并且返回旧数据 –> 数据不一致
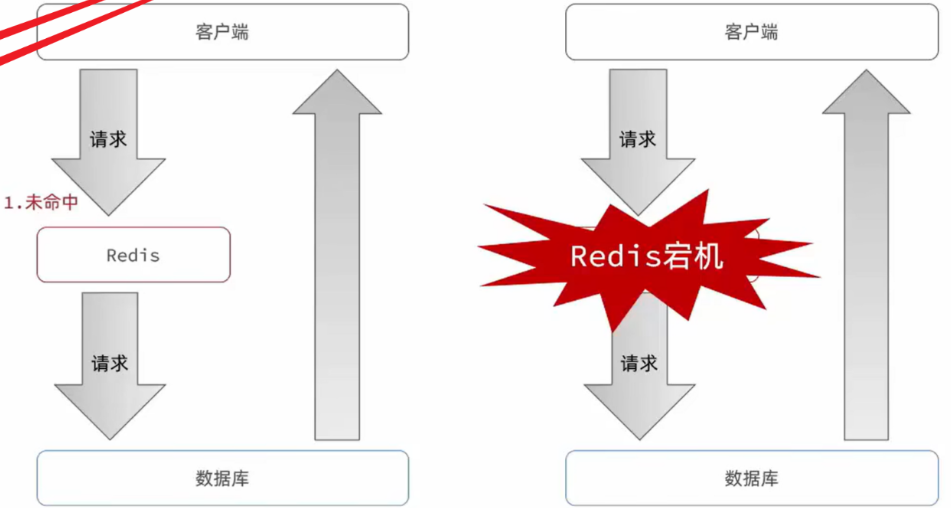
缓存雪崩
指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
- 给不同的Key的TTL添加随机值 –> 防止同时失效
- 利用Redis集群 –> planB
- 给缓存业务添加降级限流策略 –> 限制访问防止DB垮
- 给业务添加多级缓存
 !
!